Abstract
With the rise of GenAI, power delivery became one of the largest limiting factors in building and operating datacenters for AI workloads. However, we observe that not all energy consumed during training directly contributes to end-to-end throughput, and a significant portion can be removed without slowing down training, which we call energy bloat.
In this work, we identify two independent sources of energy bloat in large model training and propose Perseus, a training system that mitigates both. To do this, Perseus obtains the “iteration time–energy” Pareto frontier of any large model training job using an efficient graph cut-based algorithm and schedules the energy consumption of computations across time to reduce both types of energy bloat. Evaluation on large models like GPT-3 shows that Perseus reduces the energy consumption of large model training by up to 30% with little throughput loss and no hardware modification.
The Energy Bottleneck
"We would probably build out bigger clusters if we could get the energy to do it."
"No one has built a 1 GW datacenter yet. I think it will happen. This is only a matter of time."
-- Mark Zuckerberg's interview with Dwarkesh Patel
Exponentially growing things only do so until they hit a bottleneck, which becomes the next big challenge to solve. Today, energy is one of such bottlenecks for GenAI. People need more compute (usually from GPUs) to train and serve large models, but it's very difficult to get access to electricity which ultimately powers those hardware.12
The goal of Perseus is to reduce the total energy consumption of large model training without slowing down training by finding and removing energy wastage during training, which we call energy bloat. This leads to both less total energy consumption and lower average power draw.
Energy Bloat
The core idea of energy bloat is that if some computation is running at an unnecessarily fast speed, it may be wasting energy. Perseus identifies two independent sources of energy bloat for training pipelines (pipeline as in pipeline parallel training), and proposes an optimization method that reduces both.
Intrinsic Bloat
Large model training requires the distribution of work across multiple GPUs using a combination of multiple parallelization methods. The core observation of Perseus is that especially for pipeline parallelism, work cannot be perfectly split and balanced across every GPU; some GPUs have more work to do and some less. GPUs with smaller amounts of work finish before GPUs with more amounts of work, but ultimately training throughput is bound by GPUs with the most amount of work. In other words, GPUs with lighter load are running unnecessarily fast and generating energy bloat.
Extrinsic Bloat
In large scale training that involves tens of thousands of GPUs, stragglers (or slowdowns) become a reality -- hardware and software faults, slowdowns due to thermal and power throttling, data pipeline stalls, and more. When GPU stragglers emerge, the training pipeline (among multiple data parallel pipelines) that contains the straggler GPU will slow down, and every other pipeline must wait for the straggler pipeline to finish before they can synchronize gradients and move on to the next iteration. This means that when a straggler pipeline emerges, running other pipelines at their full speed is wasting energy -- they can slow down and reduce energy bloat.
Reducing Energy Bloat
To reduce intrinsic bloat, we need to precisely slow down select computations in the pipeline without affecting its end-to-end iteration time. On the other hand, to reduce extrinsic bloat, we need to figure out how to make the whole pipeline slower, while keeping intrinsic bloat low.

To do so, Perseus pre-characterizes every GPU frequency plan on the Iteration time--energy Pareto frontier upfront. Every frequency plan on this Pareto frontier has low intrinsic bloat, and when a straggler pipeline emerges, Perseus can simply look up the frequency plan that leads to the right pipeline iteration time on the frontier and deploy it to all non-straggler pipelines.
You can also see Perseus's optimizer in action:
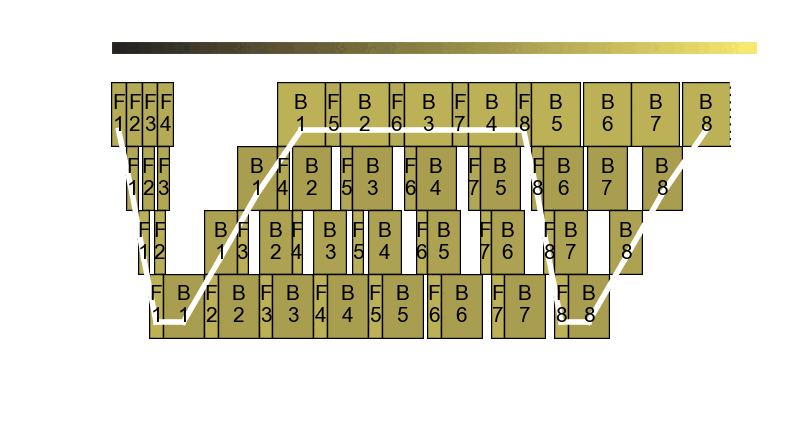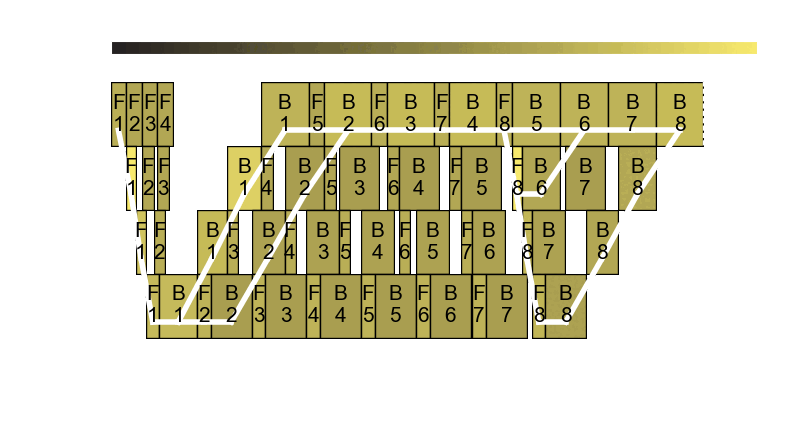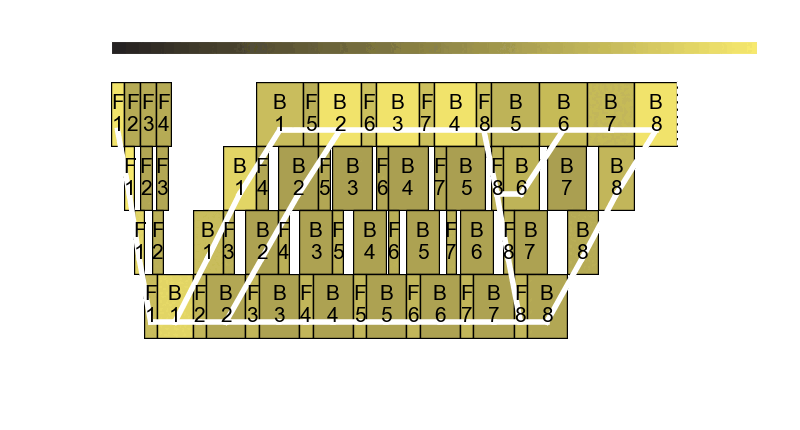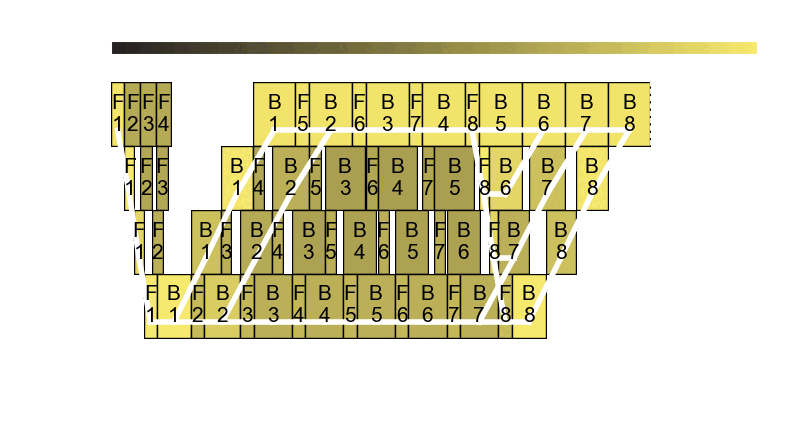
As you can see, Perseus controls the GPU frequency of each forward and backward computation in one training pipeline. One training pipeline is actually a DAG of computations. Assigning the right GPU frequency to each computation while controlling the end-to-end execution time of the DAG and minimizing its total energy consumption happens to be an NP-Hard problem, but Perseus introduces a cool graph cut-based algorithm that produces high-quality approximate solutions. Check out the algorithm in our paper!
Using Perseus
Perseus is open-sourced as the Pipeline Frequency Optimizer. It's still in early-stage development and we have a lot of sharp edges to cut, but we're hoping to talk more with the community to drive its development. Let's chat!
-
CBRE, Global Data Center Trends 2023, https://www.cbre.com/insights/reports/global-data-center-trends-2023 ↩
-
CBRE, Global Data Center Trends 2024, https://www.cbre.com/insights/reports/global-data-center-trends-2024 ↩